
スペイン語の音声認識ソフトで遊ぶ
スペイン語作文の方法という本を買ってみました。
 |
 | スペイン語作文の方法(表現編) [ 小池 和良 ] |
真面目にも2冊とも購入して、読んでみたけれど本の内容は私よりも更に更に真面目だったので目下、積読しています。
この本にはCDが付いているので例文の発音が全部聴けるのだけど、どうせなら文字起こしして見たくなったので、例によってスペイン語そっちのけで音声認識プログラムの調査メモを残しておきます。
アルゴリズム選び
まず初めに10 Greatest Open Source Speech Recognition Systems [2021]という記事を読んで、日本語技術ブログでの評判を加味するとJuliusかESPnetが紹介記事も多くてとっつきやすそうでした。
以下は何となくの各アルゴリズムの調査結果。
KaldiとJuliusは割と古い頃から今でも使われている安定感のあるソフトだそうです。(Juliusは日本の大学が公開している国産ソフト)
今回はインストールコマンド一発ですぐ動かしたいので、丁寧にインストール方法が書かれているのですがこれらは見送り。
その他、今はやりのDeepLearningだとDeepSpeech(2)、ESPnet(2)、OpenSeq2Seqが紹介記事が多くとっつきやすそうだったのですが、やはりインストールの敷居が高そうなので同じく見送り。
そもそもESPnetのmodel zooを見ても明らかなように、仮に上のソフトをインストール出来てもスペイン語の学習済みモデルは無くて自力で作るしかなさそうでした。
音声のテキスト起こしではなくてスペイン語音声->英語テキストの翻訳なら幾つかあるので、きっと語族が同じだと翻訳精度が高くて英語モデルで何とかなってしまうからなんだろうか?…
その点、言語体系的に孤立している日本は探せば学習済みモデルが見つかるので心強い。
この手のフルスペック(?)DeepLearning系統で唯一スペイン語学習済みモデルを見つけられたのはNvidiaのNeMoで、ドキュメントもしっかりしています。
(スペイン語モデルのリンク:STT Es Quartznet15x5)
恐らくUbuntuならサクッとインストール出来そうですが、手元にWindowsしか無かった為に何も考えずにpipでのインストールをしてみたら見事にコケました。
余談ですが、検索結果のサイトを見ているとauto speech recognitionやらspeech to textやら音声認識やら表記ゆれが大きいのですが基本的には全部同じ意味です。
スペイン語の音声認識モデル
結局成功したのは、最初から多言語対応を謳っているVoskで、軽量なモデルを目指しているだけあって本当にあっさりとインストールに成功。
pip install vosk公式のドキュメントではpip3でやっていますが、windowsではpipコマンドで普通に成功しました。
次に、学習モデルのダウンロードですがダウンロードサイトのvosk-model-small-es-0.3を落として解凍しておきます。
後は、pythonサンプルコード通りに動かすだけですが一応フォルダ構成のメモが下記。
test.wav
test_simple.py
model
つまり同じフォルダに2つのファイルとダウンロードしたモデルのフォルダ(名前をmodelと変更)があれば動きます。
試しにサンプルのtest.wavをスペイン語作文の構文編、構文1の音声(espanol1.wavとした)に変えて実行すると下の画像の感じで一番最後に認識した文が表示されます。
(実行コマンド -> python test_simple.py espanol1.wav)
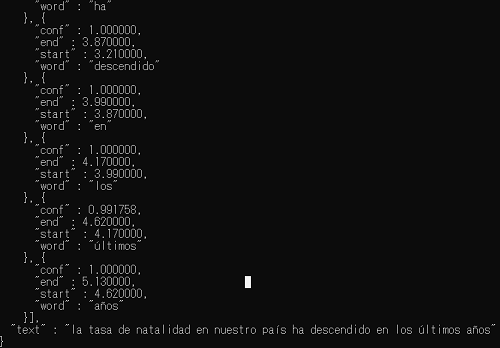
学習用CDだけあって相当明瞭に発音されているのか、モデルが凄いのか各単語のconfが0.99以上…
気が向いたら今度はyoutubeや歌などの音声を入れて遊んでみたいと思います。


