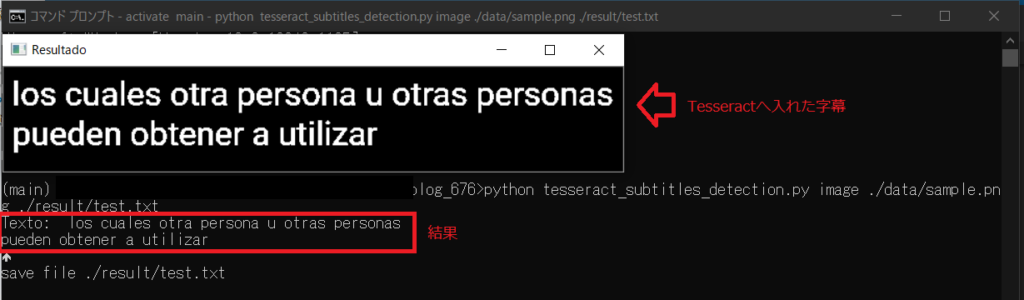
pythonでyoutube動画からスペイン語の文字起こしをする
TesseractとopenCVを使ってやってみようと思います。windowsユーザー向け。
Table of Contents
動画の用意
先ずはyoutube動画を用意します。
windows10ならWindowsキー+Gでキャプチャするのが一番簡単だと思います。
今回はOpenWebinarsチャンネル内にある動画のスペイン語字幕をONにしてやってみたものを紹介します。
pythonのライブラリ用意
Tesseractをwindowsへインストールするスペイン語解説記事を見つけたので先ずはその通りに。
Tesseract at UB Mannheimからインストーラーをダウンロード。

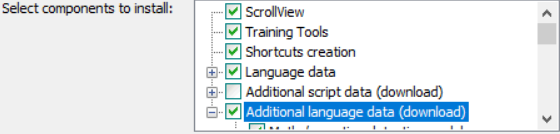
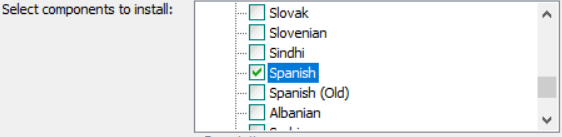
インストーラーのインストールオプションのところで、Additional language dataをチェックしてスペイン語を選択。
以上でインストール完了。
次はインストールしたTesseractをpythonで使うためにPytesseractをインストール。
pip install pytesseract上のコマンドで完了ですが、一応Pytesseract のリンクはesta páginaです。(この言葉を使ってみたかっただけ)
後はopenCVのインストールも同様に
pip install opencv-python
字幕の位置調べ
サンプルのキャプチャ動画は字幕が一番大きい時で左端(815pix,370px)右端(890,1150)なので、プログラムで判定するときは全体からそこだけ切り取って使います。

毎回調べるのがめんどくさい場合はOpenCVのEAST text detectorなどで大体の位置を自動判定させるといいと思います。
コーディング
gitで公開していますので、全体を見たい方はgitを参照してください。(tesseract_subtitles_detection.py)
以下では中身をざっくりと説明します。
tesseract.exeのパスを設定する。(大体はCドライブのProgram Filesの中にあるハズ)
字幕の位置を切り取る為に変数を設定する。
字幕の色を決める。今回は白黒にして処理するので、210よりも白い色だけ抽出。(0は真っ黒で255は真っ白)
def detect()について
前半は字幕部分を切り取る、白黒(2値化)にする、白い部分の面積を計算すると下処理をしています。
if文以降の後半は検出した白い部分のノイズを取るために処理なので、動画によって調整してください。
最後に処理が終わった画像をpytesseractへ渡しています。
def img()とdef video()はファイルからデータを読み込んでdef detect()へ画像データを渡す処理です。
動画の場合は毎フレーム字幕が変わることは無いので、取り合えず1秒おきに取得するようにしています。
最後はtxtへ書き込んで終了する流れになっています。