
スペイン語文章の読みやすさを判定する
英語にはFlesch–Kincaidの可読性スコアなるものが存在していて、wikiによると学校の教科書や海軍・陸軍の教科書の評価、自動車保険契約の目安などに使われているそうです。
このスコアのスペイン語版を探してみたところFernández HuertaやSzigriszt Pazosが提案しているモデルを見つけました。
スコアを出す英語用の式は下記の通り。
206.835 – 1.015($\frac{Total \ words}{Total \ sentences}$) – 84.6($\frac{Total \ syllables}{Total \ words}$)
式だけ見るとどうやら可読性というのは単語数や音節数で割り出されるそうで、これはスペイン語版も同じです。
英語版と違うのは主に係数部分だけです。
Fernández 版:206.84 – 1.02($\frac{Total \ words}{Total \ sentences}$) – 60($\frac{Total \ syllables}{Total \ words}$)
Szigriszt 版: 206.835 – 62.3(($\frac{Total \ syllables}{Total \ words}$) – ($\frac{Total \ words}{Total \ sentences}$) )
学習者から見ると構文の難しさや使われている単語のレベルなどが無いと腑に落ちない値になりそうな気がするのですが、ネイティブ間での読みやすさであればさもありなん。
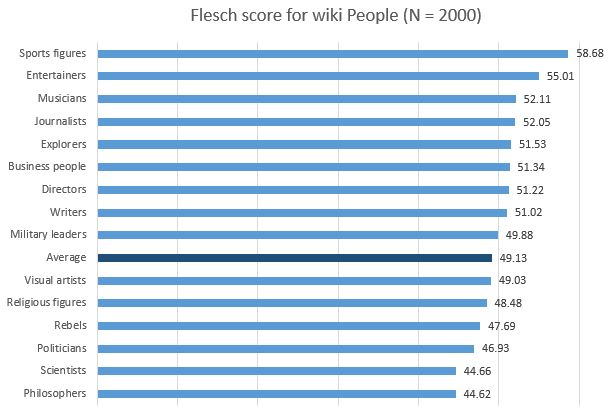
英語版のwikiで実験されている通り、教科書的な内容以外でも一応納得出来そうなスコアが示されています。
(スポーツ選手の記事より哲学者の記事の方が難しいという結果)
今回もpython実装をしてみました。(https://github.com/samsumario/blog_public/tree/main/blog_726)
実装の参考にしたのは→https://github.com/amunozf/legibilidad
各指標の説明や文献リンクはLegibleに詳細が記載されています。
元々実装が公開されていたものとの主な違いは音節のカウンター部分です。
用意した文に対してpyverseの方がきちんとカウントされていたので、pyverseを使うようにしてみました。
元実装→https://github.com/amunozf/separasilabas
今回→pyverse
早速、以前紹介したことのある初学者向けリーディング文書が乗っているPractical Spanishの文章で計測してみました。
先ずはabsolute beginner向けの13話を計測した結果。
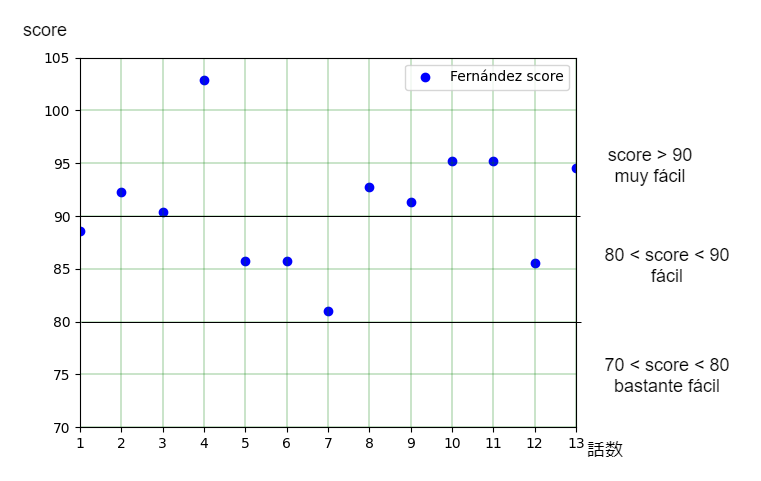
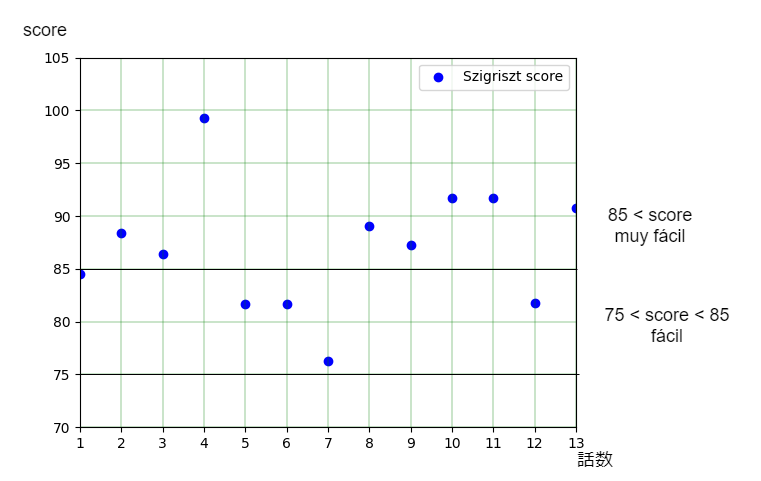
Fernándezスコアを使ってもSzigrisztを使ってもmuy fácil判定が多いです。
次はレベルが少し上がったBeginner用20話を計測した結果。
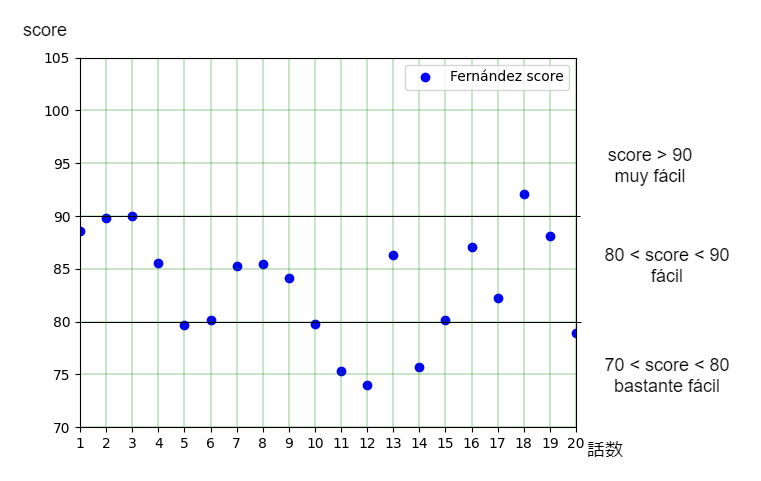
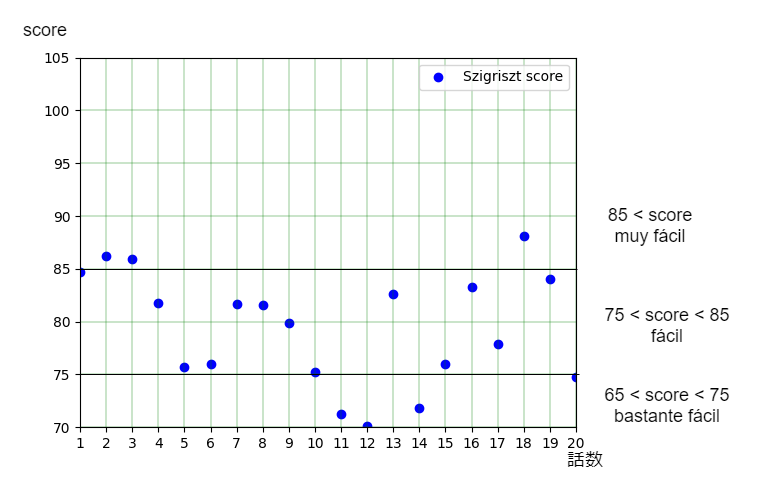
これもFernándezスコア、Szigrisztスコアともにfácil判定が多くなっていて、absolute beginnerよりもレベルが上がっていることが容易に分かります。
次回はニュースの文章を例に計測していく予定です。


