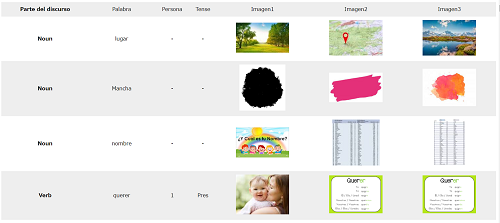
スペイン語の絵単語帳をpythonで作る
頻度リスト 名詞編
以前、自分の好きなスペイン語の歌詞を読み込ませて単語の頻度リストを作成した。
(スペイン語の歌詞で使われる単語の使用頻度解析)
今回はWikiのReal Academia Españolaが出している(はずの)頻度リストを元に名詞のリストを作成するスクリプトについて。
まずはリスト作成の元となるデータをWikiのComplete_list.zip(http://corpus.rae.es/frec/CREA_total.zip)から取得。
Windowsでそのまま開くと文字化けしてしまったので、修正したものをgitにアップロード。(gitリンク:10000_formas.txt)
あとはこのTXTファイルを上から順に読み込んで、名詞を見つけたらpythonのリストに格納するだけ。スクリプトは下記。
https://github.com/samsumario/blog_public/blob/main/blog_576/frequency_noun_list.py
一応、大雑把に関数だけ掲載。 名詞を見つける為にspaCyを使用しています。
spaCyのインストールはスペイン語向けの自然言語処理を参照。
#ファイルを読み込んで名詞だけのリスト作成
def main(data_file, save_file):
nlp = spacy.load("es_core_news_sm")
result_noun_list = []
with open(data_file, encoding = "utf_8", errors = "ignore") as f:
frequency_word_data = f.readlines()
read_header = False
for line in frequency_word_data:
if(read_header == False):
read_header = True
else:
line_list = line.split("\t")
print("\r" + "read line" + line_list[0], end="")
word = line_list[1]
if len(word) > 0:
result = []
w = nlp(word)
if(w[0].pos_ == "NOUN") or (w[0].pos_ == "PROPN"):
result.append(line_list[0].replace(" ", "").replace(".", "")) #add Order
result.append(w[0].lemma_) #add Noun
result_noun_list.append(result)# リストをそのままtxtファイルに書き出す
def save_list_data(save_file,noun_list):
with open(save_file, "w", encoding = "utf-8") as f:
for data in noun_list:
f.write(data[0] + "\t" + data[1] + "\n")
print("\nsave list in " + save_file)
このままでは少しも面白くない単語の羅列なので、google画像検索で各名詞の検索結果画像を取得してhtmlのテーブルとして出力してみる。
出力も簡素なテンプレートのhtmlファイルを用意して特定の場所に検索結果を書き込むだけ。
https://github.com/samsumario/blog_public/blob/main/blog_576/generate_noun_table_html.py
上記スクリプトも大雑把に説明すると、先ずは必要なライブラリをインストール
pip install requests
pip install bs4
pip install lxml
次にgoogleのイメージ検索から画像のurlをランダムに3つ取得する部分の関数を掲載。
(ランダムに取得する理由は検索結果ページの何個目の画像からが結果なのかまで調べていないので…)
def search_image(data):
request = requests.get("https://www.google.com/search?hl=es&q=" + data + "&btnG=Google+Search&tbs=0&safe=off&tbm=isch")
html = request.text
soup = bs4.BeautifulSoup(html,"lxml")
links = soup.find_all("img")
links_src = []
for i in range(0,3):
links_src.append(random.choice(links).get("src"))
return links_src最後にBeautifulSoup(bs4)でhtmlのテーブルを自動生成。
コードが長いわりにやっていることはテーブルにひたすら単語リストと画像リンクを書き殴っているだけ。
def main(search_word_list, html_file, template_file):
with open(template_file, mode = "rt", encoding = "utf-8") as f:
soup = bs4.BeautifulSoup(f.read(), "html.parser")
#table header
tr = soup.new_tag("tr")
th = soup.new_tag("th")
th.string = "Orden"
td_header_list = ["Palabra","Imagen1","Imagen2","Imagen3"]
for td_txt in td_header_list:
td = soup.new_tag("td")
td.string = td_txt
#append table elements
soup.find("table").append(tr)
tr.append(th)
tr.append(td)
#table content
for data in search_word_list:
data = data.split("\t")
print("\r" + "search " + data[1][0:-1], end="")
tr = soup.new_tag("tr")
th = soup.new_tag("th")
th.string = data[0]
td = soup.new_tag("td")
td.string = data[1]
#append table elements
soup.find("table").append(tr)
tr.append(th)
tr.append(td)
#search image 先ほど作った関数をつかって画像リンク取得
links = search_image(data[1])
for link in links:
td = soup.new_tag("td")
img = soup.new_tag("img",src=link)
td.append(img)
tr.append(td)以上長々となってしまったけれど、frequency_noun_list.pyとgenerate_noun_table_html.pyの大雑把な説明。
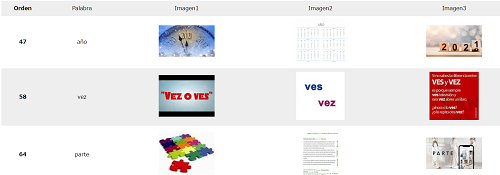
頻度リスト動詞編
やっていることは名詞と大して変わらず、人称と時制の情報をリストに追加しただけ。 (frequency_verb_list.py:39行目~)
htmlの生成スクリプトも、リストに足されたデータ分テーブルを増やしているだけ。(generate_verb_table_html.py:67行目~)
名詞と同じく下の画像のようなテーブルが出来るハズ。
実行結果はverb_list.html
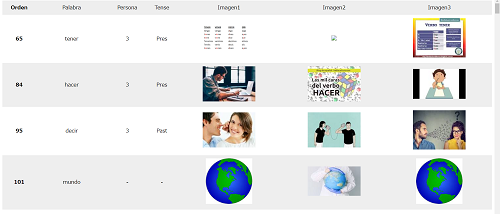
文章からの単語リスト生成編
殆ど上のスクリプトのコピペですが、何かのテキストから単語帳を生成するスクリプトも作成してみました。
動詞と名詞だけピックアップしてリスト化しています。
コードリンク:sentence_to_word_table_html.py
実行結果:word_list.html
例えば単語が分からなくて読めないニュース記事なんかをtxtにコピペして使うような用途を考えています。