スペイン語の周波数
日本人が英語が苦手な理由として言語の周波数を例に挙げて説明しているケースがよくあります。
曰く言語によって使う周波数が大きく違うので慣れが必要とか、聞き慣れるには若いうちに勉強する必要があるそう。
何となく尤もらしい気がしますが流石に周波数が大きく違うという論拠は無理があるというか雑な話なようで検索結果の半分ぐらいは反論記事です。
英語圏にも伝わっているようでradditでもLanguages use different frequenciesというタイトルのコメント欄で反論されています。
話題になっている記事の多くは日本語(が使っている?)周波数は125~1500Hzなのに対して、英語は2000~12000Hzというグラフを出しています。
実は私も初めて記事を読んだときは音楽的な知識が浅いせいもあって周波数の数字を無視して素直に納得しました。
論に違和感を感じないのは英語のピッチの方が日本語に比べて変化量が大きいという事がよく指摘されている為だと思います。
ピッチの付け方に突っ込んで解析して中国語ピッチで英語を話すことで中国語なまりの英語を再現している動画なんかもあります。
因みに周波数グラフで指摘されている英語の一番低い側の周波数2000Hzはどのぐらいの高音なのかピアノを例にして考えてみます。
ざっくりとグランドピアノの鍵盤の真ん中にあるド(C4)が261.6Hzで1オクターブ上がるとつまりド(C5)は523.3Hzとなっています。

1オクターブ上がると周波数が倍になるように作られています。(参考:音階周波数)
つまり英語の周波数2000~12000Hzとはグランドピアノの右端の方の音で話している事になり、もし本当に2000~12000Hzが語学学習に影響を及ぼすほど強いのであれば男性は一体どうやって英語を話せばいいのか途方に暮れることになります。
実は基本的には普通の声で話すのであれば言語に依らず50~300Hz程度だそうで、より詳細に言えば言語差以前に個人差がとても大きく、男性は85~180Hzで女性は165~255Hzの間が一般的だそうです。
(参考 : language pitch)
一方で50~300Hzの間であれば確かに先のyoutube動画のように各言語によってかなり特徴がある事については同意できるかと思います。
面白いことにこの言語毎の周波数表は学習関連の記事以外でも賃貸やマンションにおける防音関係の記事でも取り上げられている場合もあります。
部屋の防音はある意味で語学学習より遥かに切実な問題ですが基本的には100Hz~2000Hzをカットするのが良いそうで、一万ヘルツはもはや別の音源の為でしょう。
(騒音の種類と防音対策:https://www.annoise.com/sound/index.html)
では誰が英語と日本語の周波数が大きく違うのかと言い出したのかwebで見つかる範囲で調べてみるとNTTコミュニケーションの論文や分子生物学者の福岡伸一氏の日経のコラムと出典を書いているサイトが多いです。
原典ではどうやらこの言語毎の周波数差は「言語パスバンド」と主張されているもので、子音の強さがこの周波数論の根拠だそう。
この言語パスバンド外の音は非母語者からすると「聞こえるが、言語音として認識されずらい」そうです。
どのぐらい認識が辛いのか論文に書いてあるのかは分かりませんが初めて英語を聞いたときにsとthの違いは確かに分かりずらいと言うのは同意できます。
(パスバンド理論参考:http://yatanokarasude.gozaru.jp/tei/sikou/sikou31_081107_passband.htm)
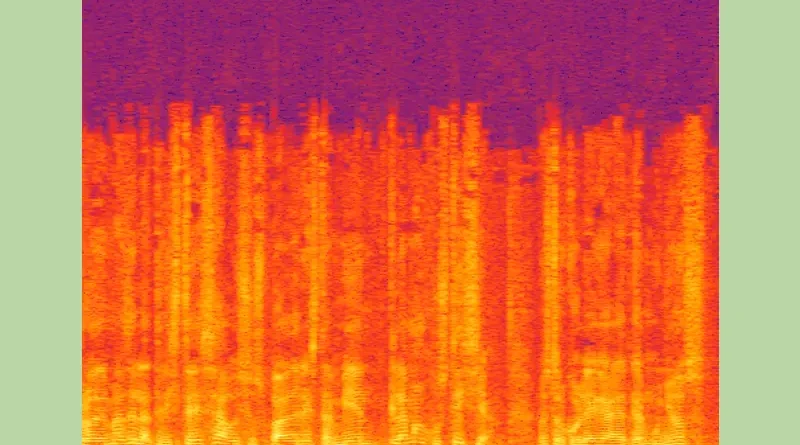
具体的に周波数にどんな特徴があるのか素人なりにスペイン語と日本語のスペクトログラムを作ってみました。
先ずはスペイン語ニュース。
解析した番組は2月17日のNoticias Telemundoから冒頭のシリアスな調子でニュースを読んでいる部分を切り取って使いました。
(番組リンク:https://www.youtube.com/watch?v=dJ8uq3Q_N_A)
音としては1万5千Hzぐらいまで出ています。2000Hz以下の部分を拡大すると以下になります。
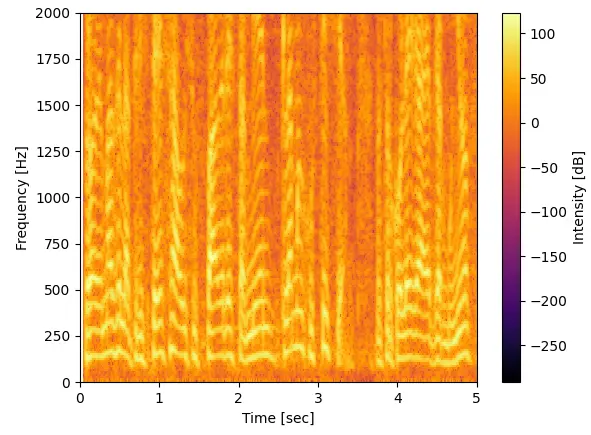
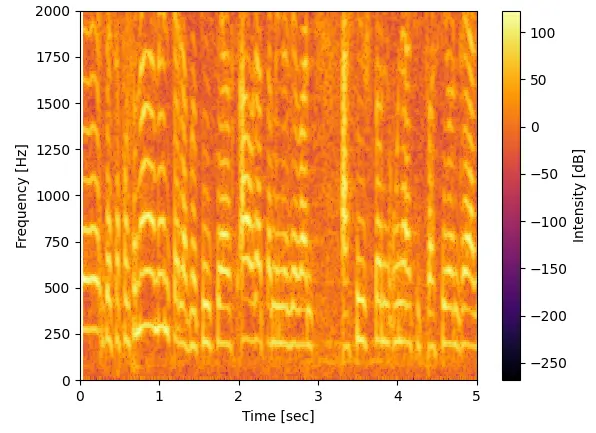
同じ波形で周波数の整数倍の部分は恐らく倍音と呼ばれるやつで基底の周波数は記事(language pitch)で紹介されている通り50Hz~250Hz帯で出ていそうです。
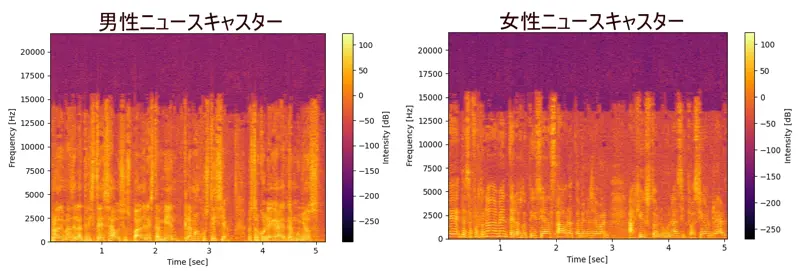
次は日本語ニュースの音声を使ってみました。
政治ニュースを読み上げている男性の声と天気予報を読み上げている女性の声をそれぞれ5secづつスペイン語と同じ条件で解析。
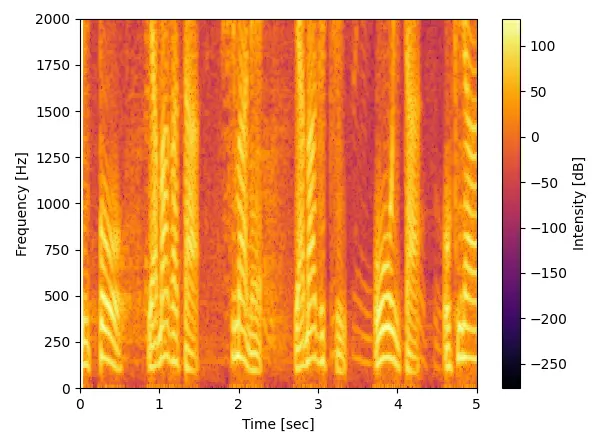
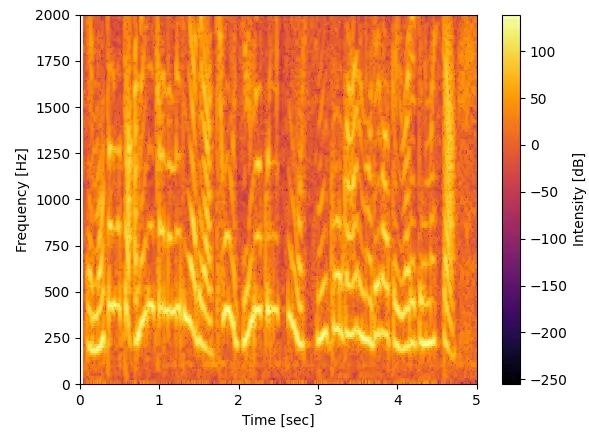
スペイン語と違うと言えば違いますがこういうデータは統計的に見ないと何とも言えなさそうです。
最後におまけで合成音声でも比較してみました。
合成音声は以前無料で使えるスペイン語の文章読み上げソフトで紹介したeSpeakを使ってwavファイルを作りました。
音声はwindows音声パックのスペイン国(女性)とメキシコ(女性)、日本語(女性)の3パターンです。
スペイン語はLorcaの詩、日本語は枕草子を読み上げさせて適当な所5secを切り取りました。

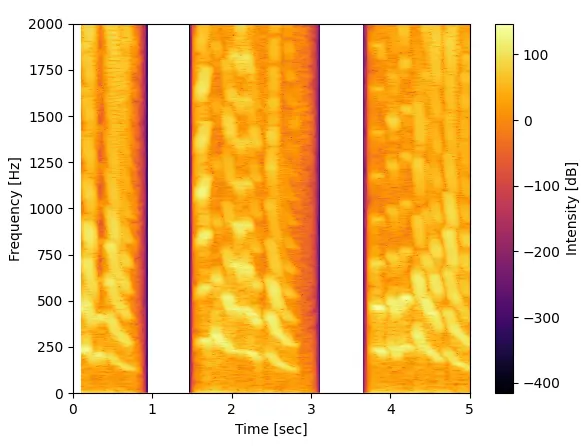

日本語の天気予報のデータもそうでしたが、何となく日本語の女性話者は周波数強度が立つ場所がピンポイントであるような気がします。
スペインもメキシコも大差は無いように見えますが、メキシコの方がちょっと日本語の周波数分布に似ているせいか私は聞きやすかったです。
解析コードについて
解析に使ったコードを説明します。
いつも通りgitにアップロードしてあるので、解説不要の人はリンクからどうぞ(https://github.com/samsumario/blog_public/tree/main/blog_2915)
先ずはwavファイルの読み込みで今回はscipyを使用しました。
ステレオサウンドの場合は左chのみ使っています。
# load wav file
samplerate, data = wavfile.read('file_name.wav')
time = data.shape[0] / samplerate
print("file length = {} sec".format(time))
# stereo to mono
if(len(data.shape) > 1):
data = data[:,0] #Left channel次にscipyのスペクトログラム解析。と言っても一行で終わります。
ちなみにscipyの関数である短時間フーリエ変換(STFT)とスペクトログラムは何が違うかと言うとざっくりと同じ認識で良いそうです。
N=512*7
freqs, times, Sxx = signal.spectrogram(data, fs=samplerate, window='han', nperseg=N, noverlap=N-100)コード中のspectrogramの戻り値Sxxはリファレンスを読むとそのまま素直に[dB]扱いしても良さそうですがバグ(?)があるそうで、matplotlibでプロットするときは更に処理をかけます。
(参考 : 短時間フーリエ変換を用いたスペクトログラムとPython実行方法の概要)
最後にデータのプロット処理。
# graph setting
plt.pcolormesh(times, freqs, 10 * np.log(np.abs(Sxx)), cmap = 'inferno')
plt.ylim([0, 2000])
plt.xlim([0, 5])
plt.ylabel('Frequency [Hz]')
plt.xlabel('Time [sec]')
cbar = plt.colorbar()
cbar.ax.set_ylabel("Intensity [dB]")
plt.show()10*np.log(np.abs(Sxx))が例のバグ処理部。


